⚡
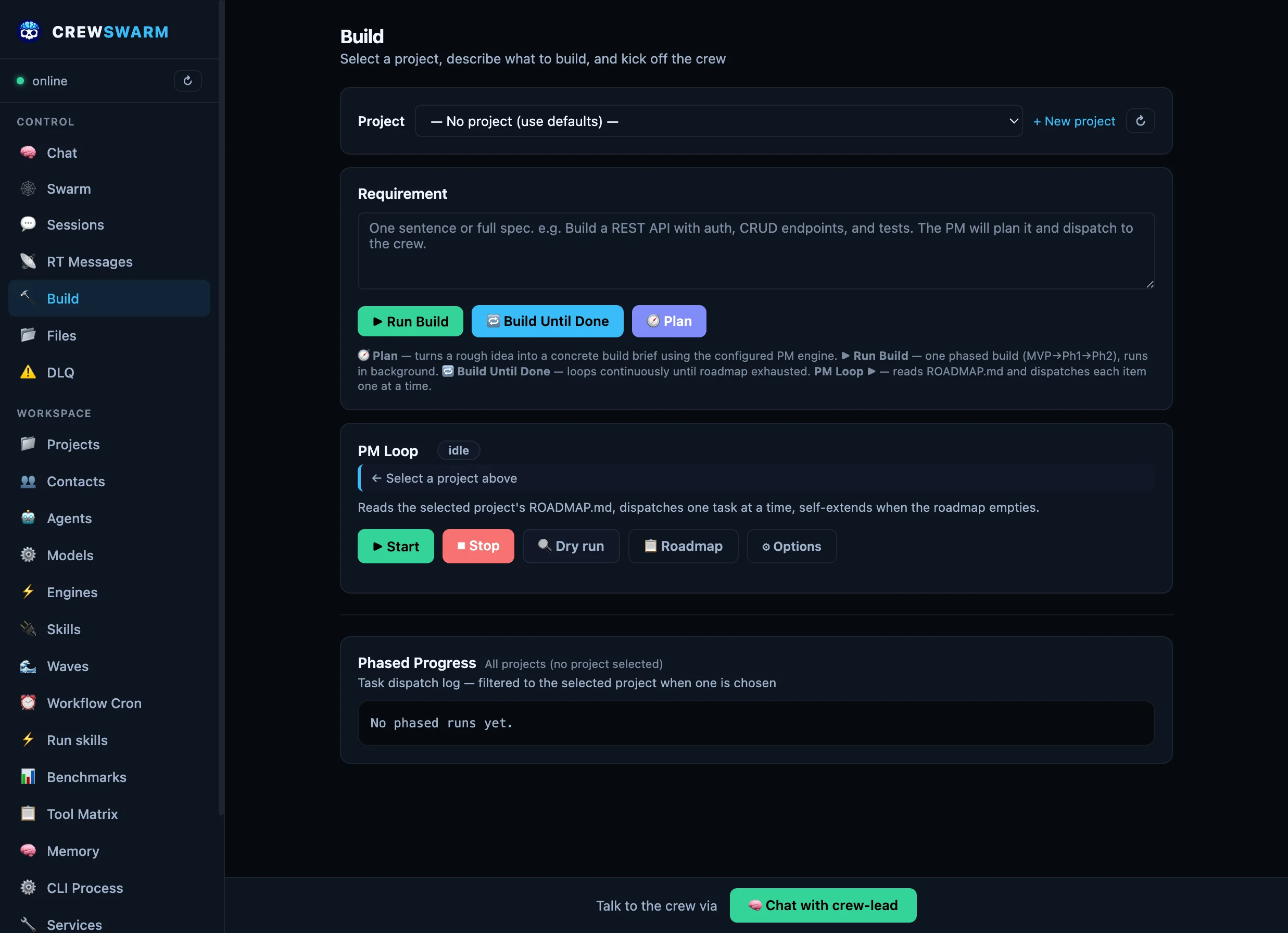
PM-led orchestration
Natural-language requirement → PM breaks it into tasks → targeted dispatch to the right agent. No broadcast
races. No duplicate work.
crew-pm → crew-coder → crew-qa → crew-fixer
🎯
Targeted dispatch
Send to one agent by name. --send crew-coder "Build auth". Only that agent receives it.
📐
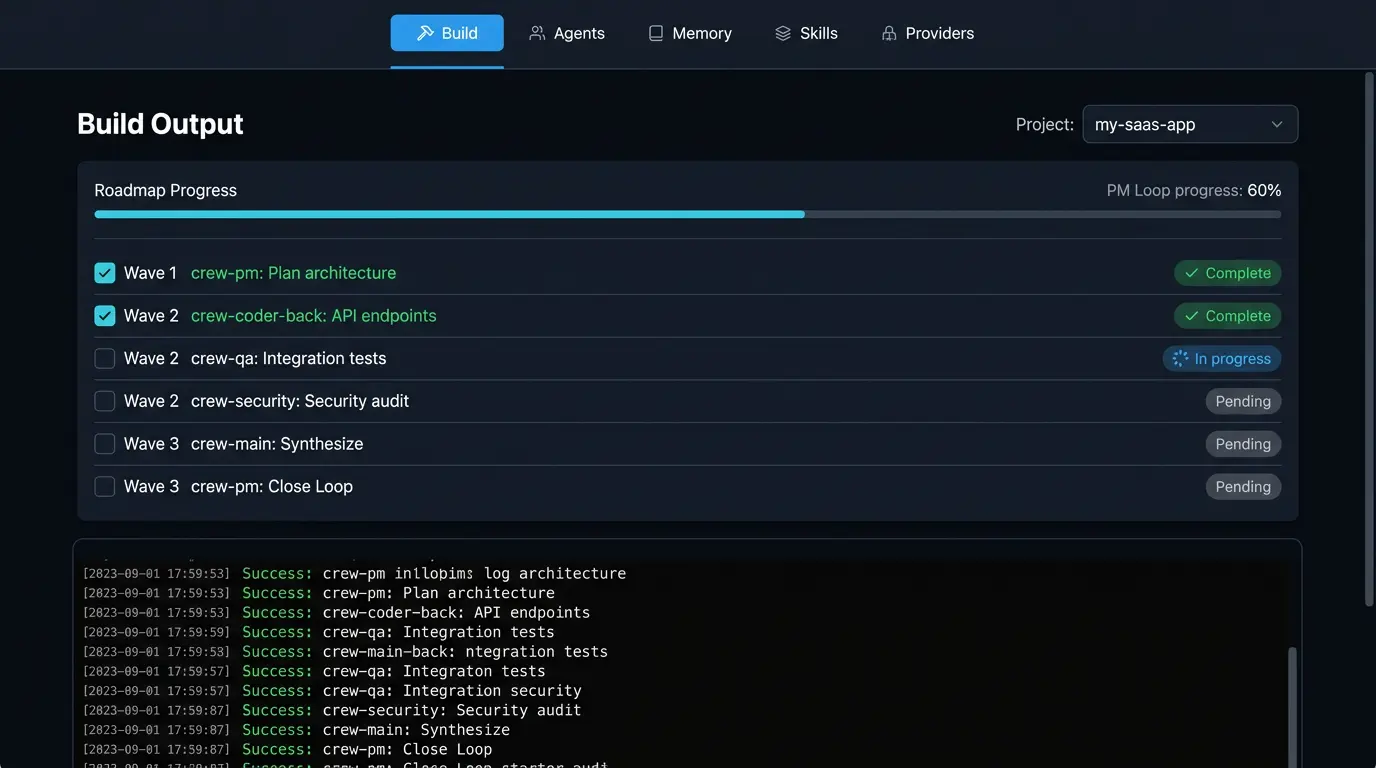
Phased builds (PDD)
MVP → Phase 1 → Phase 2. Failed tasks auto-break into subtasks and retry. No work is lost.
🧩
Domain-Aware Planning
Large codebases (100K+ lines) get subsystem-specific PM agents. crew-pm-cli handles CLI tasks,
crew-pm-frontend owns dashboard, crew-pm-core manages orchestration. No more hallucinated file paths.
🧠
Shared Memory + Project Message RAG
Every agent reads shared memory (brain.md, decisions, handoff notes). All project messages auto-save to
~/.crewswarm/project-messages/ and are automatically indexed for semantic
search using local TF-IDF + cosine similarity — no API calls, all local.
- Cognitive facts (decisions, constraints, preferences)
- Written by @@BRAIN commands
- Persists across all sessions
- All chat saved to JSONL automatically
- Semantic search: "What did we discuss about auth?"
- Export to markdown, JSON, CSV
- Task results from completed work
- Gateway records after execution
- Available to all future agents
Cache headers prevent stale data. Messages persist across
tab switches. Zero configuration needed.
🔌
Skill-powered
Extend agents with data-driven SKILL.md or JSON plugins, plus PreToolUse/PostToolUse hooks for fine-grained control. Add Twitter, Fly.io, or custom API
tools without writing JS code.
🎤
Multimodal Support — Images + Voice across all platforms
Send images or voice messages from any surface. Dashboard, Telegram, WhatsApp, and crewchat all support
image recognition and voice transcription. Powered by Groq (fast/cheap ~$3/month) or Gemini 2.0 Flash (best
quality).
📱 Dashboard
Click 📷 to upload images, 🎤 to record voice messages
💬 Telegram/WhatsApp
Send photos or voice notes → auto-analyzed and transcribed
🍎 crewchat
Native image picker + AVFoundation voice recording
🐦
Real-time X/Twitter Intelligence with Grok
The only AI coding platform with live X/Twitter search. Use @@SKILL grok.x-search to search
recent tweets, get citations with X post URLs, filter by date ranges, handles, and media types. Powered by
xAI's Grok 3 with real-time X data access.
- Search recent tweets (last 24-48 hours)
- Filter by handles, date ranges, media types
- Citations with X post URLs
- Image analysis with grok-vision-beta
- Screenshot analysis and UI audits
- Diagram and chart interpretation
Competitive edge: GitHub Copilot can't search X. Claude
can't search X. Only crewswarm has real-time X intelligence.
🐳
Docker-First Deployment — Multi-Arch Images
One-line install on any Linux machine. Multi-arch images (AMD64 + ARM64) for servers, VMs, Raspberry Pi,
cloud deployments, and CI/CD. Perfect for team shared instances, GitHub Actions, or self-hosted setups.
curl -fsSL https://raw.githubusercontent.com/crewswarm/crewswarm/main/scripts/install-docker.sh | bash
AWS, GCP, DigitalOcean, Azure
Raspberry Pi 4/5, NUCs, edge devices
GitHub Actions, GitLab CI, Jenkins
Shared crew for entire team
Local dev setup also available for contributors. Pick the
deployment that fits your workflow.
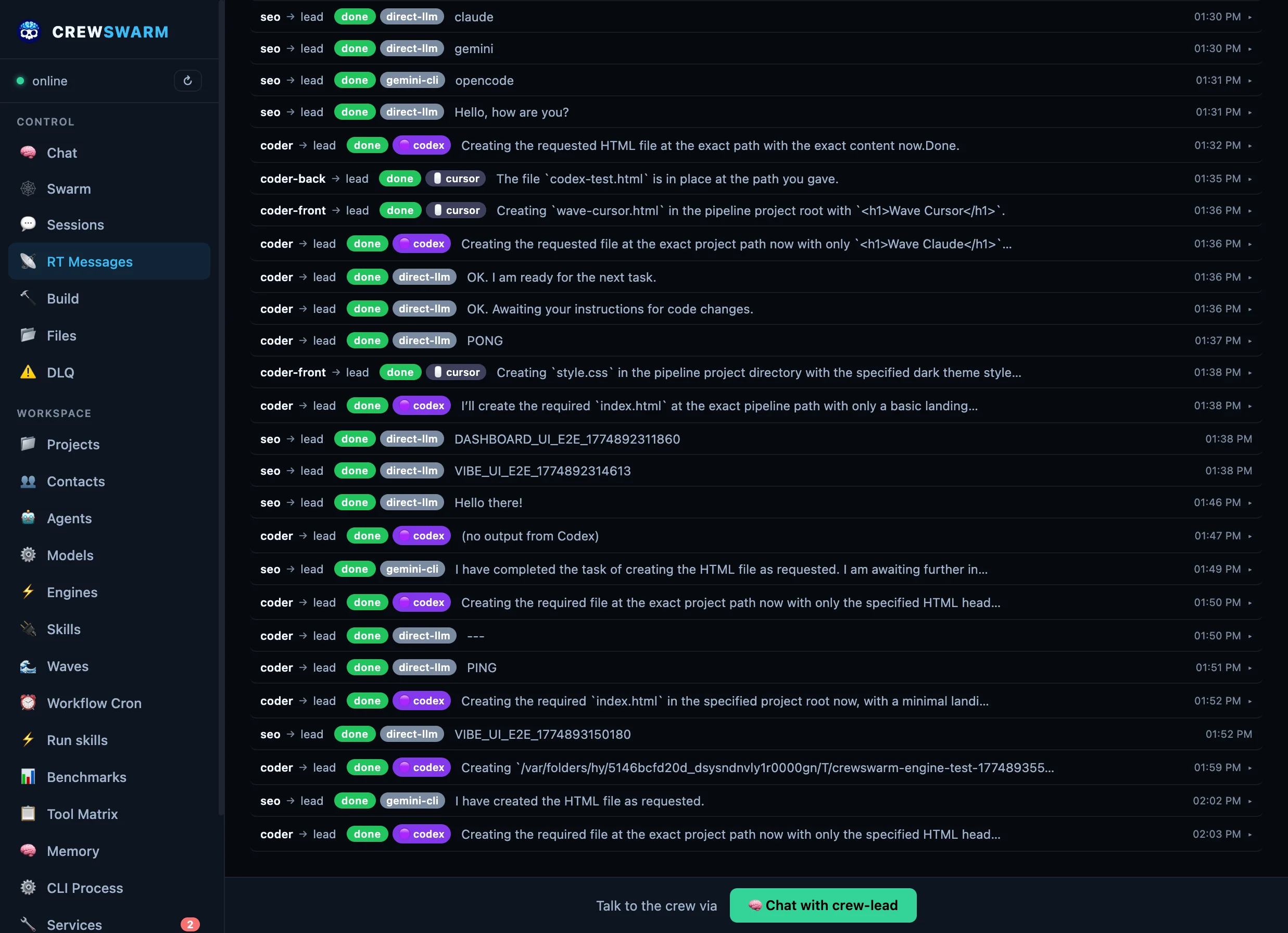
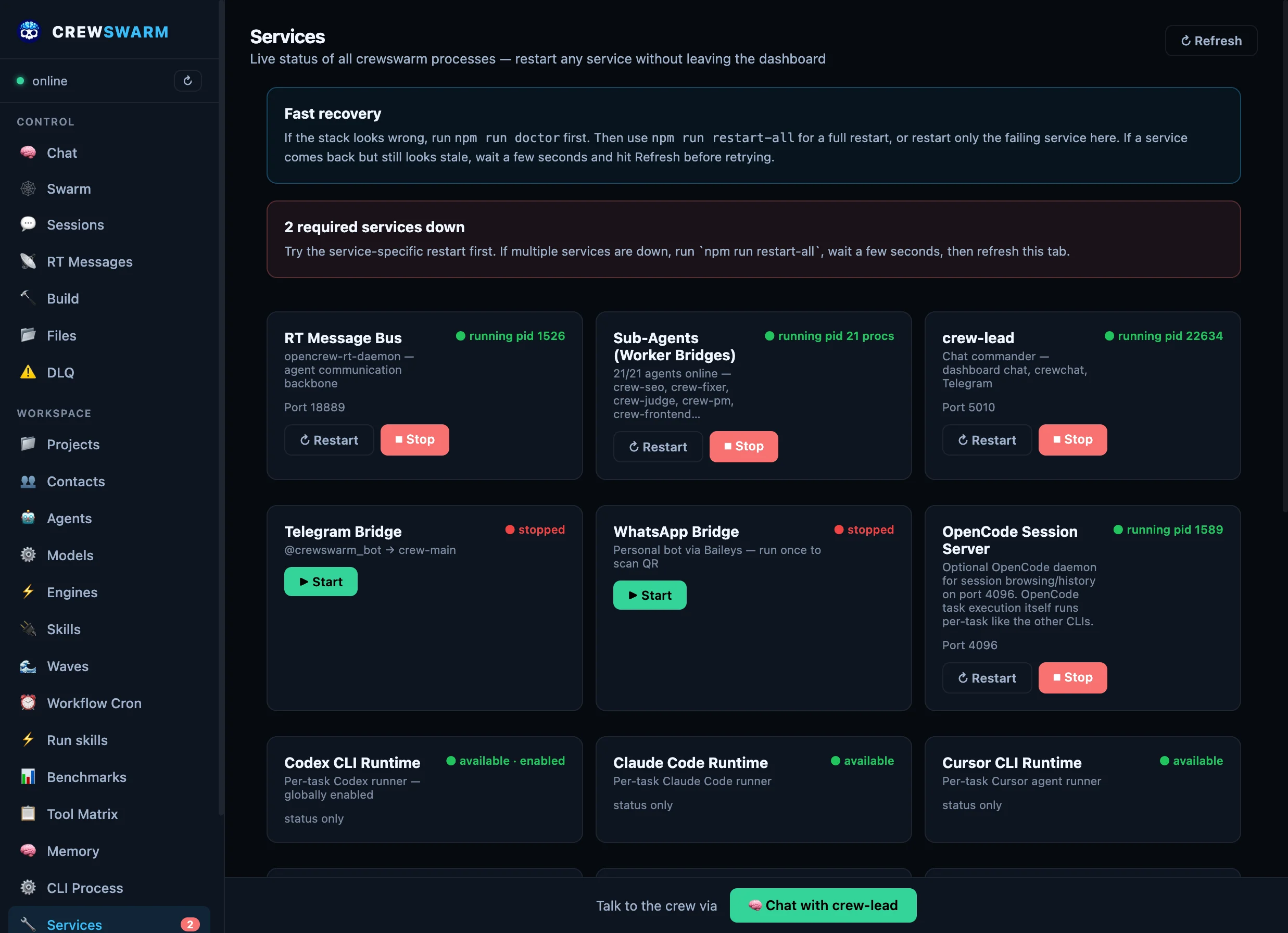
🔄
Fault tolerance
Retry with backoff and task leases. After max retries, tasks hit the Dead Letter Queue for manual replay
from the dashboard.
🚀
Six execution engines — your choice per agent
Your crew runs specialist AI agents (PM, coder, QA, fixer…) — each one calling its LLM directly. For heavy
coding tasks, agents can go deeper: route them into OpenCode, Cursor CLI,
Claude Code, Codex CLI, crew-cli, or Gemini CLI for full file
editing, bash access, and persistent sessions. Switch per agent from the dashboard. No restarts, no config
files.
- Persistent sessions per agent
- Full file editing + bash
- Context survives across tasks
Best for: crew-coder, crew-fixer, crew-coder-front/back
- opus-thinking + sonnet-4.6
- Deep reasoning & architecture
- Parallel wave dispatch
Best for: crew-main, crew-architect, complex reasoning
- Full workspace context
- Native Anthropic tool use
- Session continuity per agent
Best for: large refactors, multi-file reasoning
- 3-Tier AI Architecture (Router/Planner/Worker)
- 3x Parallel Speedup over sequential cycles
- ATAT Protocol & LSP
Self-Healing enabled
Best for: High-performance terminal engineering
- OpenAI's agentic coding CLI
- Full sandbox + file editing
- No approval prompts — just executes
Best for: crew-coder-back, fast backend iteration
- Google Gemini 2.0 Flash / Pro — stream-json output
- Fast inference, multimodal support
- Non-interactive
--yolo mode
Best for: Fast iterations, Google-model workflows
🔌
MCP server — your crew in any AI tool
crewswarm exposes your entire crew as an MCP server on port 5020. Add one line to
~/.cursor/mcp.json (or Claude Code, OpenCode, Codex) and every project gets your full
persistent agent fleet — not session-scoped generics, but your crew with memory, custom models, and
cross-agent coordination.
- Send a task to any specialist agent
- Waits for the result
- Full tool access + memory
- Multi-agent chains from any client
- Each stage passes output to the next
- PM → coder → QA in one call
- Talk to crew-lead directly via MCP
- Run any skill (deploy, TTS, webhooks…)
- OpenAI-compatible API on same port
~/.cursor/mcp.json →
{"mcpServers":{"crewswarm":{"url":"http://127.0.0.1:5020/mcp"}}}
⚙️
@@ Protocol — 10x more efficient than JSON-RPC
While others use verbose JSON-RPC or natural language, crewswarm agents communicate via a proprietary
@@ syntax that's 10x more token-efficient, unambiguous, and easy for LLMs
to generate. MCP-compatible via translation layer.
{"tool": "write",
"params": {
"path": "app.ts",
"content": "import express..."
}}
~80 tokens •
Fragile
@@WRITE_FILE app.ts
import express from 'express';
const app = express();
...
@@END_FILE
~8 tokens • 10x
less overhead
Why @@ wins:
- Zero ambiguity — Regex-parseable, no JSON errors
- Inline with prose — Explain AND execute in one message
- LLM-friendly — Easy to generate from prompt examples
- Cost savings — 10x fewer tokens = cheaper API bills
Graceful Failure:
Unlike JSON, CAP is
stream-parseable. If a model hits a context limit halfway through writing 4 files, the first 3 are still
valid and executed. In JSON, you lose the whole turn.
Available commands: @@READ_FILE • @@WRITE_FILE • @@RUN_CMD
• @@DISPATCH • @@PIPELINE • @@SKILL • @@WEB_SEARCH • @@MEMORY
🖥️
Seven control surfaces
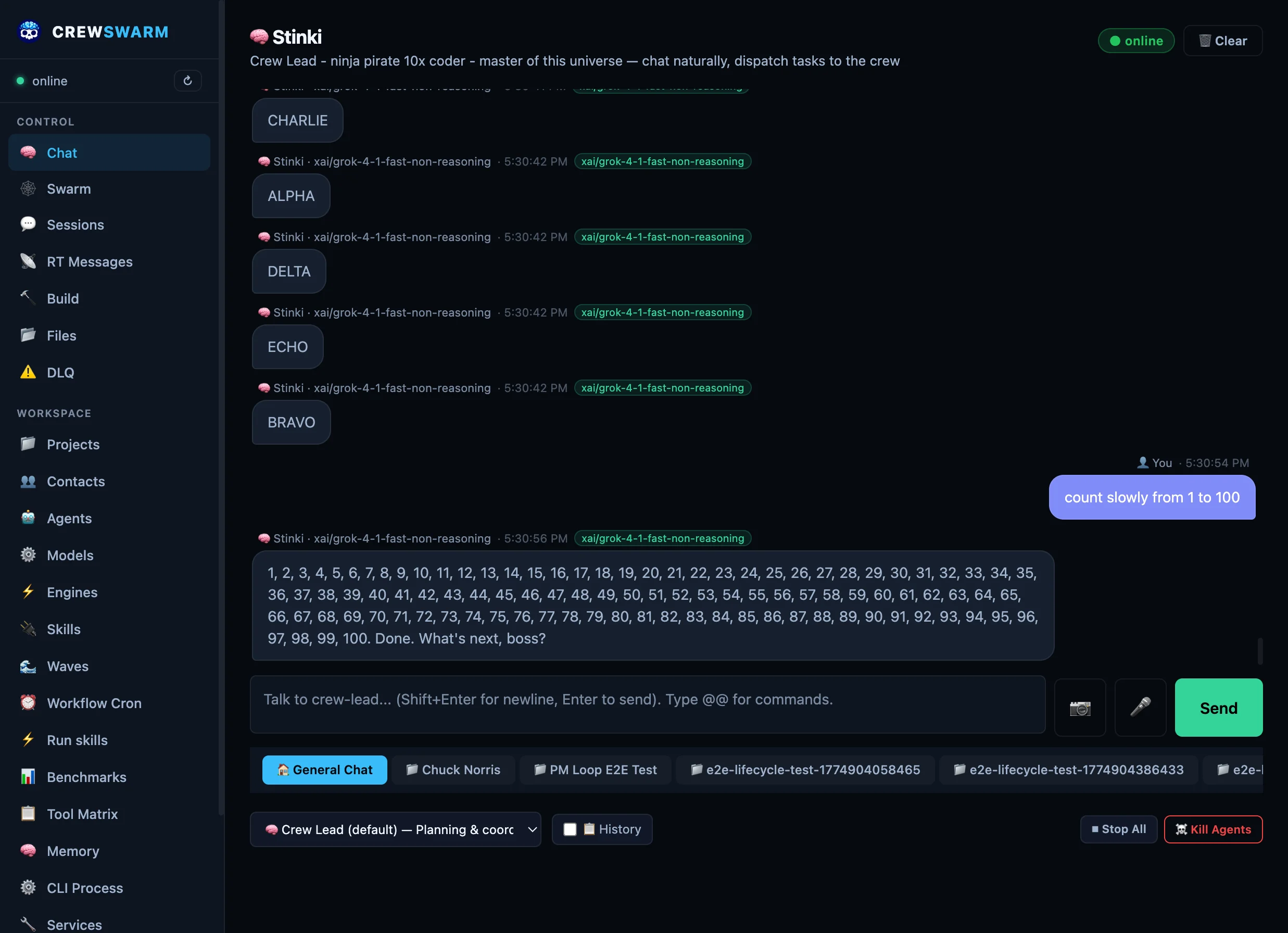
Pick how you want to drive the crew. Every surface talks to the same RT bus and the same agents.
Chat with Stinki
Dashboard
Full web UI — chat, build, services, RT bus, DLQ, spend
crewswarm Vibe
Browser-native IDE with Monaco — real-time file tree + agent chat.
crewchat
Quick & Advanced modes — multimodal image + voice support.
REST API / CLI
curl /chat · direct dispatch · scheduled pipelines
Mobile messengers
Telegram
Message Stinki from your phone — same conversation as Dashboard
WhatsApp
Personal bot via Baileys — QR scan once, then chat from WhatsApp
Monitoring & control
Dashboard
Services · RT bus · DLQ replay · spend · agent health
SwiftBar
macOS menu bar — status, quick restart, agent logs